Subsections
A function call is an expression of the form:
functionName(arg1, arg2)
A function can have any number of arguments, including zero.
Arguments can be specified by position or by name (name overrides
position). Arguments are optional if they have a default value.
This section provides a list of some of the functions
that are useful for working with data in R. The
descriptions of these functions is very brief and only some
of the arguments to each function are mentioned. For a complete
description of the function and its arguments, the relevant
function help page should be consulted.
- c(...)
-
Concatenate or combine values (or vectors of values)
to make a vector. All values must be
of the same type (or they will be coerced to the same type).
This function can be used to concatenate lists.
- seq(from, to, by, length.out)
-
Generate a sequence of values from from to (not greater than)
to in steps of by for a total of length.out values.
- rep(x, times, each, length.out)
-
Repeat all values in a vector times times, or
each value in the vector each times, or all
values in the vector until the total number of values
is length.out.
- sum(..., na.rm=FALSE)
-
Sum the value of all arguments. Arguments should be vectors, but,
for example, matrices will be accepted. If NA values
are included, the result is NA (unless na.rm=TRUE).
This function is generic.
-

-
Calculate the minimum, maximum, or range of all values in all arguments.
-
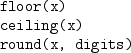
-
Round a numeric value to a number of digits or to an integer value.
floor() returns largest integer not greater than x and
ceiling() returns smallest integer not less than x.
- identical(x, y)
-
Tests whether two objects are equivalent down to the binary storage level.
- all.equal(target, current, tolerance)
-
Tests whether two numeric values are effectively equal (i.e., only
differ by a tiny amount, as specified by tolerance).
Subsetting is generally performed via the [ operator
(e.g., candyCounts[1:4]). In general, the result
is of the same class as the original object that is being
subsetted. The subset may be numerical indices, string names,
or a logical vector (the same length as the original object).
When subsetting objects with more than one dimension, e.g., data frames,
matrices
or arrays, the subset may be several vectors, separated by commas
(e.g., candy[1:4, 4]).
The [[ operator selects only one component of an object.
This is typically used to extract a component from a list.
- subset(x, subset, select)
-
Extract the rows of the data frame x that satisfy the
condition in subset and the columns that are named
in select. The advantage of this over the normal
subset syntax is that column names are searched for within
the data frame (i.e., you can use just count; no need for
candy$count).
- rbind(...)
-
Create a new data frame by combining
two or more data frames that have the same columns.
The result is the union of the rows of the original data frames.
This function also works for matrices.
- cbind(...)
-
Create a new data frame by combining
two or more data frames that have the same number of rows.
The result is the union of the columns of the original data frames.
This function also works for matrices.
- merge(x, y)
-
Create a new data frame by combining two data frames
in a database-join operation. The two data frames will
usually have different columns, though they will typically
share at least one column, which is used to match the rows.
The default join is a natural join.
Additional arguments allow for the equivalent of inner joins
and outer joins.
- aggregate(x, by, FUN)
-
Call the function FUN for each subset of x
defined by the grouping factors in the list by.
It is possible to apply the function to multiple variables
(x can be a data frame) and it is possible
to group by multiple factors (the list
by can have more than one component).
The result is
a data frame. The names used in the by list are used
for the relevant columns in the result.
If x is a data frame, then the names of the variables
in the data frame are used for the relevant columns in the result.
- sweep(x, MARGIN, STATS, FUN)
-
Take an array and add or subtract (more generally, apply
the function FUN) the STATS values from the
rows or columns (depending on value of MARGIN).
For example, remove column means from all columns.
- table(...)
-
Generate table of counts for one or more factors.
The result is a "table" object, with as many
dimensions as there were arguments.
- xtabs(formula, data)
-
Similar to table() except factors to cross-tabulate are
expressed in a formula. Symbols in the formula will be searched
for in the data frame given by the data argument.
- ftable(...)
-
Similar to table() except that the result is always
a two-dimensional "ftable" object, no matter
how many factors are cross-tabulated. This makes for a more
readable display.
- apply(X, MARGIN, FUN, ...)
-
Call a function on each row or each column of a data frame
or matrix.
The function FUN is called for each row of the matrix
X (if MARGIN equals 1; if
MARGIN is 2, the function is called for each
column of X). All other arguments are passed as
arguments to FUN.
The data structure that is returned depends on the value
returned by FUN. In the simplest case, where
FUN returns a single value, the result is a
vector with one value per row (or column) of the original
matrix X.
- tapply(X, INDEX, FUN, ...)
-
Call a function once each subset of the vector X, where the
subsets correspond to unique values of the factor INDEX.
The INDEX argument can be a list of factors, in which case
the subsets are unique combinations of the levels of the factors.
The result depends on how many factors are given in INDEX.
For the simple case, where there is only one factor, and FUN
returns a single value, the result
is a vector.
- lapply(X, FUN, ...)
-
Call the function FUN once for each component of the
list X. The result is a list.
- sapply(X, FUN, ...)
-
Similar to lapply(), but will simplify the result to
a vector if possible (e.g., if all components of
X are vectors and FUN returns a single value).
- sort(x)
-
Put a vector in order. For sorting by more than one factor,
see order().
- order(...)
-
Calculate an ordering of one or more vectors (all the same length).
The result is a numeric vector, which can be used, via subsetting,
to reorder another vector.
- with(data, expr)
-
Run the code in expr and search within the variables of the
data frame specified by data for any symbols used in expr.
- readLines(con)
-
Read the text file specified by the file name and/or path in con.
The file can also be a URL.
The result is a string vector with one element for each line in the file.
- read.table(file, header, skip, sep)
-
Read the text file specified by the string value in file,
treating each line of
text as a case in a data set that contains values for each variable
in the data set, with values separated by the string value in sep.
Ignore the first skip lines in the file.
If header is TRUE, treat the first line of the file
as variable names.
The result is a data frame.
- read.fwf(file, widths)
-
Read a text file in fixed-width format. The name of the file is
specified by file and widths is a numeric vector
specifying the width of each column of values.
The result is a data frame.
- read.csv(file)
-
A front end for read.table() with default argument settings
designed for reading a text file in CSV format.
The result is a data frame.
- scan(file, what)
-
Read data from a text file and produce a vector of values.
The type of the value provided for the argument what
determines how the values in the text file are interpreted.
If this argument is a list, then the result is a list of
vectors, each of a type corresponding to the relevant
component of what.
This function is faster than read.table() and its kin.
- grep(pattern, x)
-
Search for the regular expression pattern in the string
vector x and return a vector of numbers, where each
number is the index to a string in x that matches pattern.
If there are no matches, the result has length zero.
- gsub(pattern, replacement, x)
-
Search for the regular expression pattern in the character
vector x and replace all matches with the string value in
replacement. The result is a vector containing the modified strings.
- substr(x, start, stop)
-
For each string in x, return a substring consisting of the
characters at positions start through stop inclusive.
The first character is at position 1.
- strsplit(x, split)
-
For each string in x, break the string into separate strings,
using split as the delimiter. The result is a list,
with one component for each string in the original vector x.
- paste(..., sep, collapse)
-
Combine strings together, placing the string sep in between.
The result is a string vector the same length as the longest
of the arguments, so shorter arguments are recycled.
If the collapse argument is not NULL, the result vector
is collapsed to a single string, with the string collapse placed
in between each element of the result.
The help() function is special in that it provides information
about other functions. This function displays a help page, which is
online documentation that describes what a function does. This includes
an explanation
of all of the arguments to the function and a description of the
return value for the function.
Figure 12.1 shows the beginning of the help
page for the sleep() function, which is obtained by
typing help(Sys.sleep).
Figure 12.1:
The help page for the function Sys.sleep() as displayed
in a Linux system. This help
page is displayed by the expression help(Sys.sleep).
Sys.sleep package:base R Documentation
Suspend Execution for a Time Interval
Description:
Suspend execution of R expressions for a given number of
seconds
Usage:
Sys.sleep(time)
Arguments:
time: The time interval to suspend execution for, in seconds.
Details:
Using this function allows R to be given very low priority
and hence not to interfere with more important foreground
tasks. A typical use is to allow a process launched from R
to set itself up and read its input files before R execution
is resumed.
|
A special shorthand using the question mark character, ?,
is provided for getting the help page for a function.
Instead of typing help(Sys.sleep) it is also possible
to simply type ?Sys.sleep.
Many help pages also have a set of examples to
demonstrate the proper use of the function and these
examples can be run using the example() function.
There are many thousand R functions in existence.
They are organised into collections of functions called packages.
A number of packages
are installed with R by default and several packages are loaded
automatically in every R session. The search() function
shows which packages are
currently available, as shown below:
> search()
[1] ".GlobalEnv" "package:stats" "package:graphics"
[4] "package:grDevices" "package:utils" "package:datasets"
[7] "package:methods" "Autoloads" "package:base"
The top line of the help page for a function
shows which package the function comes from.
For example, Sys.sleep() comes from the
base package (see Figure 12.1).
Other packages may be loaded using the
library() function.
For example, the foreign package provides functions for reading
in data sets that have been stored in the native format of a different
statistical software system. In order to use the read.spss()
function from this package, the foreign package must be loaded
as follows:
> library(foreign)
The search() function confirms that the
foreign package is now loaded and all of the
functions from that package are now available.
> search()
[1] ".GlobalEnv" "package:foreign" "package:stats"
[4] "package:graphics" "package:grDevices" "package:utils"
[7] "package:datasets" "package:methods" "Autoloads"
[10] "package:base"
There are usually 25 packages distributed with R. Over a thousand
other packages are available for download from the web via the
Comprehensive R Archive Network
(CRAN).12.2
These packages must first be installed before they
can be loaded. A new
package can be installed using the install.packages()
function.
Given the name of a function, it is not difficult to find
out what that function does and how to use the function
by reading the function's help page.
A more difficult job is to find the name of a function
that will perform a particular task.
The help.search() function can be used to search for functions
relating to a keyword within the current R installation
and the RSiteSearch() function performs
a more powerful and comprehensive
web-based search of functions in almost all
known R packages, R mailing list archives,
and the main R manuals.12.3
There is also a Google customised search
available12.4 that provides
a convenient categorisation of the search results.
Another problem that arises is that, while information on a single
function is easy to obtain, it can be harder to discover how
several related functions work together.
One way to get a broader overview of functions in a package
is to read a package vignette (see the
vignette() function). There are also overviews
of certain areas of research or application provided by
CRAN Task Views (see http://cran.r-project.org)
and there is a growing list of books on R.
Paul Murrell

This document is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 License.