
|
| The Pacific Ocean is the largest body of water on Earth.1.1 |
The Pacific Ocean is the largest body of water on Earth.1.1
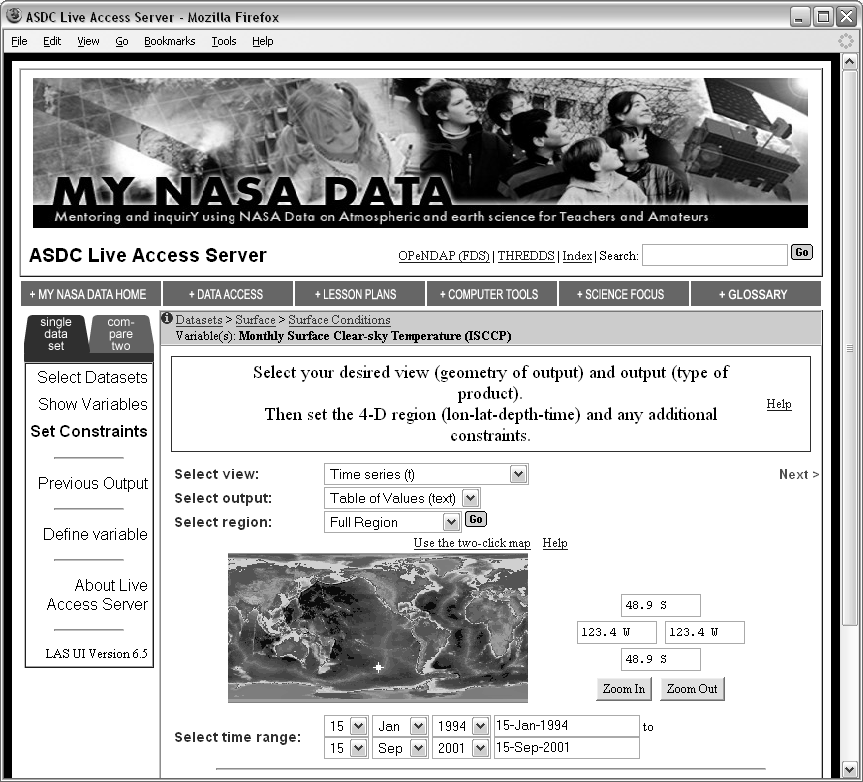
The Live Access Server is one of many services provided by the National Aeronautics and Space Administration (NASA) for gaining access to their enormous repositories of atmospheric and astronomical data. The Live Access Server1.2provides access to atmospheric data from NASA's fleet of Earth-observing satellites, which consists of coarsely gridded measurements of major atmospheric variables, such as ozone, cloud cover, pressure, and temperature. NASA provides a web site (Figure 1.1) that allows researchers to select variables of interest, and geographic and temporal ranges, and then to download or view the relevant data. Using this service, we can attempt to answer important questions about atmospheric and weather conditions in different parts of the world.
 |
The Pacific Pole of Inaccessibility is a location in the Southern Pacific Ocean that is recognised as one of the most remote locations on Earth. Also known as Point Nemo, it is the point on the ocean that is farthest from any land mass.1.3 Its counterpart, the Eurasian Pole of Inaccessibility, in northern China, is the location on land that is farthest from any ocean.1.4
These two geographical extremes--one in the southern hemisphere, over 2,500 km from the nearest land, and one in the northern hemisphere, over 2,500 km from the nearest ocean--are usually only of interest either to interpid explorers or conspiracy theorists (a remote location is the perfect place to hide an important secret!). However, we will use NASA's Live Access Server to investigate the differences in weather conditions between these interesting geographical extremes.
To make our task a little more manageable, for now we will restrict our attention to a comparison of the surface temperatures at each of the Poles of Inaccessibility. To be precise, we will look at monthly average temperatures at these locations from January 1994 to September 2001.
In a book on data analysis, we would assume that the data are already in a form that can be conveniently loaded into statistical software, and the emphasis would be on how to analyse these data. However, that is not the focus of this book. Here, we are interested in all of the steps that must be taken before the data can be conveniently loaded into statistical software.
As anyone who has worked with data knows, it often takes more time and effort to get the data ready than it takes to perform the data analysis. And yet there are many more books on how to analyse data than there are on how to prepare data for analysis. This book aims to redress that balance.
In our example, the main data collection has already occurred; the data are measurements made by instruments on NASA satellites. However, we still need to collect the data from NASA's Live Access Server. We will do this initially by entering the appropriate parameters on the Live Access Server web site. Figure 1.2 shows the first few lines of data for the surface temperature at Point Nemo.
|
VARIABLE : Mean TS from clear sky composite (kelvin)
FILENAME : ISCCPMonthly_avg.nc
FILEPATH : /usr/local/fer_dsets/data/
SUBSET : 93 points (TIME)
LONGITUDE: 123.8W(-123.8)
LATITUDE : 48.8S
123.8W
23
16-JAN-1994 00 / 1: 278.9
16-FEB-1994 00 / 2: 280.0
16-MAR-1994 00 / 3: 278.9
16-APR-1994 00 / 4: 278.9
16-MAY-1994 00 / 5: 277.8
16-JUN-1994 00 / 6: 276.1
...
|
The first thing we should always do with a new data set is take a look at the raw data. Viewing the raw data is an important first step in becoming familiar with the data set. We should never automatically assume that the data are reliable or correct. We should always check with our own eyes. In this case, we are already in for a bit of a shock.
As an antipodean, I expect temperatures to be in degrees Celsius, so values like 278.9 make me break into a sweat. Even if we expect temperatures on the Fahrenheit scale, 278.9 is hotter than the average summer's day.
The problem of course is that these are scientific measurements, so the
scale being used is Kelvin; the temperature
scale where zero really means zero. 278.9 K is 5.8
![]() C or
42
C or
42
![]() F, which is a cool, but entirely believable
surface temperature value. When planning a visit to Point Nemo,
it would be a good idea to pack a sweater.
F, which is a cool, but entirely believable
surface temperature value. When planning a visit to Point Nemo,
it would be a good idea to pack a sweater.
Looking at the raw data, we also see a lot of other information besides the surface temperatures. There are longitude and latitude values, dates, and a description of the variable that has been measured, including the units of measurement. This metadata is very important because it provides us with a proper understanding of the data set. For example, the metadata makes it clear that the temperature values are on the Kelvin scale. The metadata also tells us that the longitude and latitude values, 123.8 W and 48.8 S are not exactly what we asked for. It turns out that the values provided by NASA in this data set have been averaged over a large area so this is as good as we are going to get.
We have established that the data seem credible, but do we have any reason to believe that the data are accurate or error-free? This comes down to how the data were collected. In this case, the data were collected by machines (satellites) and only ever existed in an electronic form. In particular, no humans got in the way, and there was no need for a data entry step. This increases our level of trust in the data.1.5
We should also notice that information does not just flow from the Live Access Server to us. Information is also sent from us to the Live Access Server to specify the exact data that we require. This is done via a web-based electronic form, which has several advantages: we can only ask for data that the Live Access Server is able to supply because there are only links for the available data; we can only ask for data that makes sense, for example the form does not allow us to enter latitudes beyond 90 north or 90 south; and we can get the data immediately--we do not have to wait for the postal service to deliver a paper form to NASA. These issues of how best to collect data, and in particular how to get information from humans into electronic form is discussed in Chapter 5.
Before we go forward, we should take a step back and acknowledge the fact that we are able to read the data at all. This is a benefit of the format that the data are in; in this case, a plain text format. If the data had been in a more sophisticated binary format, we would need something more specialised than a common web browser to be able to view our data. In Chapter 7 we will spend a lot of time looking at the advantages and disadvantages of different data storage formats.
Having had a look at the raw data, the next step in familiarising ourselves with the data set should be to look at some numerical summaries and plots. The Live Access Server does not provide numerical summaries and, although it will produce some basic plots, we will need a bit more flexibility. So we will save the data to our own computer and load it into a statistical software package.
The first step is to save the data. The Live Access Server will provide an ASCII file for us, or we can just copy-and-paste the data into a text editor and save it from there. Again, we should appreciate the fact that this step is quite straightforward and is likely to work no matter what sort of computer or operating system we are using. This is another feature of having data in a plain text format.
Now we need to get the data into our statistical software. At this point, we encounter one of the disadvantages of a plain text format. Although we, as human readers, can see that the surface temperature values start on the ninth line and are the last value on each row (see Figure 1.2), there is no way that statistical software can figure this out on its own. We will have to describe the format of the data set to our statistical software.
In order to read the data into statistical software, we need to be able to express the following information: “skip the first 8 lines”; and “on each row, the values are separated by whitespace (one or more spaces or tabs)”; and “on each row, the date is the first value and the temperature is the last value (ignore the other three values)”. Here is one way to do this for the statistical software package R (Chapter 11 has much more to say about working with data in R):
read.table("PointNemo.txt", skip=8,
colClasses=c("character",
"NULL", "NULL", "NULL",
"numeric"),
col.names=c("date", "", "", "", "temp"))
This solution may appear complex, especially for anyone not experienced in writing computer code. Partly that is because this is complex information that we need to communicate to the computer and writing code is the only way to express that sort of information. However, the complexity of writing computer code gains us many benefits. For example, having written this piece of code to load in the data for the Pacific Pole of Inaccessibility, we can use it again, with only a change in the name of the file, to read in the data for the Eurasian Pole of Inaccessibility. That would look like this:
read.table("Eurasia.txt", skip=8,
colClasses=c("character",
"NULL", "NULL", "NULL",
"numeric"),
col.names=c("date", "", "", "", "temp"))
Imagine if we wanted to load in temperature data in this format from several hundred other locations around the world. Loading in such volumes of data would now be trivial and fast using code like this; performing such a task by selecting menus and filling in dialog boxes hundreds of times does not bear thinking about.
Going back a step, if we wanted to download the data for hundreds of locations around the world, would we want to fill in the Live Access Server web form hundreds of times? I most certainly would not. Here again, we can write code to make the task faster, more accurate, and more bearable.
As well as the web interface to the Live Access Server, it is also possible to make requests by writing scripts. Here is the script to ask for the temperature data from the Pacific Pole of Inaccessibility:
lasget.pl -x -123.4 -y -48.9 -t 1994-Jan-1:2001-Sep-30 \
-f txt \
http://mynasadata.larc.nasa.gov/las-bin/LASserver.pl \
ISCCPMonthly_avg_nc ts
Again, that may appear complex, and there is a “start up” cost involved in learning how to write such scripts. However, this is the only sane method to obtain large amounts of data from the Live Access Server. Chapters 9 and 11 look at extracting data sets from complex systems and automating tasks that would otherwise be tedious or impossible if performed by hand.
Writing code, as we have seen above, is the only accurate method of communicating even mildly complex ideas to a computer; and even for very simple ideas, writing code is the most efficient method of communication. In this book, we will always communicate with the computer by writing code. In Chapter 2 we will discuss the basic ideas of how to write computer code properly. We will encounter a number of different computer languages throughout the remainder of the book.
Finally, we have our data in a form that is convenient for conducting the data analysis. Because this is not a book on data analysis, this is where we stop. The important points for our purposes are how the data are collected, stored, accessed, and processed. These topics are the focus of this book.
Paul Murrell

This document is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 License.