Subsections
7.5 Plain text files
The simplest way to store information is in a plain text file.
In this format, everything is stored as text, including numeric
values.
A good example of this sort of plain text data is the surface temperature
data for the Pacific Pole of Inaccessibility (see
Section 1.1; Figure 7.3
reproduces Figure 1.2 for convenience).
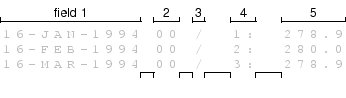
Figure 7.3:
The first few lines of the plain text output from the Live Access Server
for the surface temperature at Point Nemo. This is
a reproduction of Figure 1.2.
VARIABLE : Mean TS from clear sky composite (kelvin)
FILENAME : ISCCPMonthly_avg.nc
FILEPATH : /usr/local/fer_dsets/data/
SUBSET : 93 points (TIME)
LONGITUDE: 123.8W(-123.8)
LATITUDE : 48.8S
123.8W
23
16-JAN-1994 00 / 1: 278.9
16-FEB-1994 00 / 2: 280.0
16-MAR-1994 00 / 3: 278.9
16-APR-1994 00 / 4: 278.9
16-MAY-1994 00 / 5: 277.8
16-JUN-1994 00 / 6: 276.1
...
|
Plain text files can be thought of as the lowest common denominator of
storage formats; they might not be the most efficient or sophisticated
solution, but we can be fairly certain that they will get the job done.
A plain text file containing a data set may be referred to as a
flat file. The basic characteristics of a flat file
are that the data are stored as
plain text, even the numbers are plain text,
and that each line of the file contains one
record or case in the data set.
There may be a header
at the start of the file
containing general information, such as names of varaibles.
In Figure 7.3, the first 8 lines
are header information.
For each line in a flat file (each case in the data set),
there are usually several fields containing the values for the
different variables in the data set. There are two main
approaches to differentiating fields:
- Delimited format:
- Fields within a record are separated by
a special character, or delimiter. For example,
it is possible to view the file in
Figure 7.3 as a delimited format,
where each line after the header
consists of two fields
separated by a colon
(the character `:' is the delimiter).
Alternatively, if we used “white space” (one or more spaces or tabs)
as the delimiter, there would be five fields, as shown below.
Using a delimited format can cause problems
if it is possible for one of the values in the data set to
contain the delimiter. The typical solution to this problem is to
allow quoting of values or escape sequences.
- Fixed-width format:
- Each field is allocated a fixed number of characters. For example,
it is possible to view the file in Figure 7.3
as a fixed-width format, where
the first field uses the first 20 characters and the second field
uses the next 8 characters. Alternatively, there are five fields
using 11, 3, 2, 4, and 8 characters respectively.
With a fixed width format we can have any character as part of the
value of a field, but enforcing a fixed length for fields can be a
problem if we do not know the maximum possible length for all
variables.
Also, if the values for a variable can have very different lengths,
a fixed-width format can be inefficient because we store lots
of empty space for short values.
All text file formats have the advantage that text is easy for
humans to read and it is easy to write software to read text,
but fixed-width formats are exceptional in that
they are especially easy for humans to read because of the regular
arrangement of values.
7.5.3 Advantages of plain text
The main advantage of plain text formats is their simplicity:
we do not require complex software to create a text file;
we do not need esoteric skills beyond being able to type
on a keyboard; it is easy for people
to view and modify the data.
- Virtually all software packages can read and
write text files.
- Plain text files are portable across different computer
platforms.
- All statistics software will read/write text files.
- Most people are able to use at least one piece of software
that can read/write text files.
- People can read plain text.
- Requires only low-level interface.
The main disadvantage of plain text formats is their simplicity.
- Lack of standards:
- No standard way to specify data format.
No standard way to express “special characters”.
- Inefficiency:
- Can lead to massive redundancy (repetition of values).
Speed of access and space efficiency for large data sets.
Difficult to store “non-rectangular” data sets.
- Internationalization
- Lack of data integrity:
- lack of data integrity measures
Consider a data set collected on two families, as depicted in
Figure 7.4. What would this look like as a
flat file? One possible comma-delimited format is shown below:
John,33,male,Julia,32,female,Jack,6,male
John,33,male,Julia,32,female,Jill,4,female
John,33,male,Julia,32,female,John jnr,2,male
David,45,male,Debbie,42,female,Donald,16,male
David,45,male,Debbie,42,female,Dianne,12,female
This format for storing these data is not ideal for two reasons.
Firstly, it is not efficient; the parent information is repeated
over and over again. This repetition is also undesirable because
it creates opportunities for errors and inconsistencies to
creep in. Ideally, each individual piece of information would
be stored exactly once; if more than one copy
exists then it is possible for the copies to disagree.
We will discuss this idea more in
Section 7.9.10.
The other problem is not as obvious, but is arguably much more
important. The fundamental structure of the flat file format
means that each line of the file contains exactly one record
or case in the data set. This works well when a data set
only contains information about one type of object, or, put another way,
when the data set itself has a flat structure.
The data set of family members does not have a flat structure.
There is information about two different types of object, parents
and children, and these objects have a definite relationship between them.
We can say that the data set is hierarchical or multi-level or
stratified (as is obvious from the view of the data in
Figure 7.4).
Any data set that is obtained using a non-trivial
study design is likely to have a hierarchical structure like this.
In other words, a flat file format does not allow for
sophisticated “data models” (see Section 7.9.5).
A flat file is unable to provide an appropriate
representation of a complex data structure.
Figure 7.4:
A family tree
containing data on parents and children. An example of hierarchical data.
![\begin{figure}% the gap below seems to be important!??
\par
\includegraphics[width=\textwidth]{store-families}\end{figure}](img28.png) |
7.5.5 CSV files
Although not a formal standard, comma-separated value (CSV) files
are very common and are a quite reliable plain text delimited
format. For example,
this is a common way to export data from a spreadsheet.
The main rules for the CSV format are:
- Each field is separated by a comma (i.e., the
character `,' is the delimiter).
- Fields containing commas must be surrounded by double
quotes (i.e., the `"' character is special).
- Fields containing double quotes must be surrounded by
double quotes and each embedded double quote must
be represented using two double quotes
(i.e., `""' is an escape sequence for a literal double quote).
- There can be a single header line containing the names
of the fields.
7.5.6 Case Study: The Data Expo
The American Statistical Association (ASA) holds an annual conference
called the Joint Statistical Meetings (JSM).
One of the events sometimes held at
this conference is a Data Exposition, where contestants are provided with a
data set and must produce a poster demonstrating a comprehensive analysis of
the data. For the Data Expo at the 2006 JSM
the data were geographic and atmospheric measures obtained from NASA's
Live Access Server (see Section 1.1).
The variables in the data set are:
elevation, temperature (surface and air), ozone, air pressure,
and cloud cover (low, mid, and high).
With the exception of elevation, all variables are monthly averages,
with observations for January 1995 to December 2000.
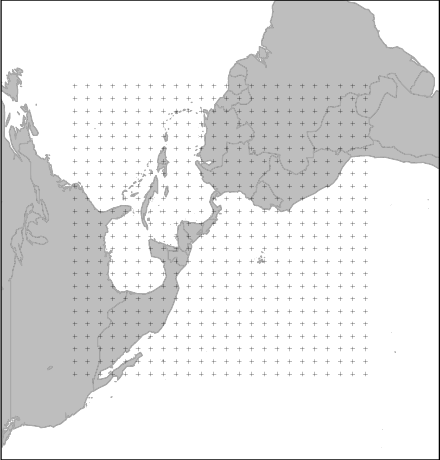
The data are measured at evenly-spaced geographic locations
on a very coarse 24 by 24 grid covering Central America
(see Figure 7.5).
Figure 7.5:
The geographic locations at which Live Access Server atmospheric data were obtained
for the 2006 JSM Data Expo.
 |
The data were downloaded from the Live Access Server with one file for each
variable, for each month; this produced 72 files per atmospheric variable,
plus 1 file for elevation, for a total of 505 files.
Figure 7.6 shows the start of one of the
surface temperature files.
Figure 7.6:
The first few lines of output from the Live Access Server
for the surface temperature of the Earth for January 1995,
over a coarse 24 by 24 grid of locations covering central America.
VARIABLE : Mean TS from clear sky composite (kelvin)
FILENAME : ISCCPMonthly_avg.nc
FILEPATH : /usr/local/fer_dsets/data/
SUBSET : 24 by 24 points (LONGITUDE-LATITUDE)
TIME : 16-JAN-1995 00:00
113.8W 111.2W 108.8W 106.2W 103.8W 101.2W 98.8W ...
27 28 29 30 31 32 33 ...
36.2N / 51: 272.7 270.9 270.9 269.7 273.2 275.6 277.3 ...
33.8N / 50: 279.5 279.5 275.0 275.6 277.3 279.5 281.6 ...
31.2N / 49: 284.7 284.7 281.6 281.6 280.5 282.2 284.7 ...
28.8N / 48: 289.3 286.8 286.8 283.7 284.2 286.8 287.8 ...
26.2N / 47: 292.2 293.2 287.8 287.8 285.8 288.8 291.7 ...
23.8N / 46: 294.1 295.0 296.5 286.8 286.8 285.2 289.8 ...
...
|
Just the storage
of this number of files presents a challenge.
First of all, the only sensible thing to do is to place these files
into a separate directory of their own. Storing these files in
a directory with other files would cause confusion, would
make it difficult to
find files, and would make it difficult to remove or modify files.
The next problem is how to name these files.
Choosing file names is a form of documentation; the name of the file
should clearly describe the contents of the file, or at least
distinguish the contents of the file from the contents of other files
in the same directory.
Another thing to consider is how the files will be ordered
in directory listings; will it be easy to browse a list of the
files in a directory and find the file we want?
When a file name contains a date, the best way to format that date is
as a number, with year first, month second, and day last. This ensures
that, when the files are alphabetically ordered, the files will be
grouped sensibly.
Paul Murrell

This document is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 License.